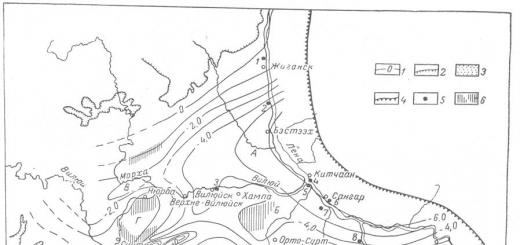
Между изменениями 7 и X. Для оценки тесноты связи между случайными переменными величинами используются показатели
Как мы уже говорили, одно из главных отличий последовательности наблюдений, образующих временной ряд, заключается в том, что члены временного ряда являются, вообще говоря, статистически взаимозависимыми. Степень тесноты статистической связи между случайными величинами Xt и Xt+T может быть измерена парным коэффициентом корреляции
Оценку генерального параметра получают на основе выборочного показателя с учетом ошибки репрезентативности . В другом случае в отношении свойств генеральной совокупности выдвигается некоторая гипотеза о величине средней , дисперсии, характере распределения, форме и тесноте связи между переменными. Проверка гипотезы осуществляется на основе выявления согласованности эмпирических данных с гипотетическими (теоретическими). Если расхождение между сравниваемыми величинами не выходит за пределы случайных ошибок, гипотезу принимают. При этом не делается никаких заключений о правильности самой гипотезы, речь идет лишь о согласованности сравниваемых данных. Основой проверки статистических гипотез являются данные случайных выборок. При этом безразлично, оцениваются ли гипотезы в отношении реальной или гипотетической генеральной совокупности . Последнее открывает путь применения этого метода за пределами собственно выборки при анализе результатов эксперимента, данных сплошного наблюдения, но малой численности. В этом случае рекомендуется проверить, не вызвана ли установленная закономерность стечением случайных обстоятельств, насколько она характерна для того комплекса условий, в которых находится изучаемая совокупность.
При этом оказывается, что корреляционные и регрессионные характеристики схемы (, т]) могут существенно отличаться от соответствующих характеристик исходной (неискаженной) схемы (, л)- Так, например, ниже (см. п. 1.1.4) показано, что наложение случайных нормальных ошибок на исходную двумерную нормальную схему (, т) всегда уменьшает абсолютную величину коэффициента регрессии Ql в соотношении (В. 15), а также ослабляет степень тесноты связи между ит (т. е. уменьшает абсолютную величину коэффициента корреляции г).
Влияние ошибок измерения на величину коэффициента корреляции. Пусть мы хотим оценить степень тесноты корреляционной связи между компонентами двумерной нормальной случайной величины (, TJ), однако наблюдать мы их можем лишь с некоторыми случайными ошибками измерения соответственно es и е (см. схему зависимости D2 во введении). Поэтому экспериментальные данные (xit i/i), i = 1, 2,. .., л, - это практически выборочные значения искаженной двумерной случайной величины (, г)), где =
Метод Р.а. состоит в выводе уравнения регрессии (включая оценку его параметров), с помощью которого находится средняя величина случайной переменной , если величина другой (или других в случае множественной или многофакторной регрессии) известна. (В отличие от этого корреляционный анализ применяется для нахождения и выражения тесноты связи между случайными величинами71.)
В изучении корреляции признаков, не связанных согласованным изменением во времени, каждый признак изменяется под влиянием многих причин, принимаемых за случайные. В рядах динамики к ним прибавляется изменение во времпш каждого ряда. Это изменение приводит к так называемой автокорреляции - влиянию изменений уровней предыдущих рядов на последующие. Поэтому корреляция между уровнями динамических рядов правильно показывает тесноту связи между явлениями, отражаемыми в рядах динамики , лишь в том случае, если в каждом из них отсутствует автокорреляция. Кроме того, автокорреляция приводит к искажению величины среднеквадратических ошибок коэффициентов регрессии , что затрудняет построение доверительных интервалов для коэффициентов регрессии , а также проверки их значимости.
Определенные соотношениями (1.8) и (1.8) соответственно теоретический и выборочный коэффициенты корреляции могут быть формально вычислены для любой двумерной системы наблюдений они являются измерителями степени тесно- ты линейной статистической связи между анализируемыми признаками. Однако только в случае совместной нормальной рас-пределенности исследуемых случайных величин и ц коэффициент корреляции г имеет четкий смысл как характеристика степени тесноты связи между ними. В частности, в этом, случае соотношение г - 1 подтверждает чисто функциональную линейную зависимость между исследуемыми величинами, а уравнение г = 0 свидетельствует об их полной взаимной независимости. Кроме того, коэффициент корреляции вместе со средними и дисперсиями случайных величин и TJ составляет те пять параметров, которые дают исчерпывающие сведения о
Случайной величиной называется величина, которая в результате опыта может принять то или иное заранее неизвестное значение.
Примерами могут служить: потери и подсосы воздуха, степень усвоения кислорода, неточности взвешивания компонентов шихты, колебания химического состава сырья в связи с недостаточным усреднением и т. д.
Соотношение, устанавливающее связь между возможными значениями случайной величины и соответствующими им вероятностями, называется законом распределения, который количественно выражается в двух формах.
Рис. 5.1 Функция распределения (а) и плотность распределения (б)
Вероятность события , зависящая от значения , называется функцией распределения случайной величины:
![]() . (5.1) есть неубывающая функция (рис. 5.1,а). Значения ее при предельных значениях аргумента равны:и.
. (5.1) есть неубывающая функция (рис. 5.1,а). Значения ее при предельных значениях аргумента равны:и.
Плотность распределения
Чаще используется другая форма закона распределения – плотность распределения случайной величины , являющаяся производной функции распределения:
. (5.2) Тогда вероятность нахождения величины в интервалеиможно выразить через плотность распределения:
 . (5.3`) Плотность распределения есть неотрицательная функция (рис. 21,б), площадь под кривой распределения равна единице:
. (5.3`) Плотность распределения есть неотрицательная функция (рис. 21,б), площадь под кривой распределения равна единице:
. (5.4) Функция распределения может выражаться через плотность распределения:
 . (5.5) Для решения большинства практических задач закон распределения , т. е. полная характеристика случайной величины, неудобен для использования. Поэтому чаще применяют числовые характеристики случайной величины, определяющие основные черты закона распределения . Наиболее распространенными из них являются математическое ожидание и дисперсия (или среднеквадратичное отклонение).
. (5.5) Для решения большинства практических задач закон распределения , т. е. полная характеристика случайной величины, неудобен для использования. Поэтому чаще применяют числовые характеристики случайной величины, определяющие основные черты закона распределения . Наиболее распространенными из них являются математическое ожидание и дисперсия (или среднеквадратичное отклонение).
Математическое ожидание
Математическое ожидание случайной величины определяется следующим образом
 . (5.6) где
. (5.6) где
Математическое ожидание случайной величиныобычно оценивается ее средним арифметическим, которое при увеличении числа опытовсходится к математическому ожиданию
 . (5.7) где - наблюдаемые значения случайной величины.
. (5.7) где - наблюдаемые значения случайной величины.
Важно отметить, что в случае, если – непрерывно меняющаяся во времени величина (температура свода, стенки, химический состав продуктов горения), то необходимо брать в качестве значения величинызначения величины , разделенные такими интервалами во времени, чтобы их можно было рассматривать как независимые опыты. Практически это сводится к учету инерционности по соответствующим каналам. Способы оценки инерционности объектов будут рассмотрены ниже.
Дисперсия и среднеквадратическое отклонение
Дисперсия определяет рассеяние случайной величины около ее математического ожидания
![]() . (5.8) Оценка дисперсии производится по формуле
. (5.8) Оценка дисперсии производится по формуле
 . (5.9) а среднеквадратического отклонения по формуле
. (5.9) а среднеквадратического отклонения по формуле
Коэффициент корреляции
Коэффициент корреляции характеризует степень линейной связи между величинамии, т. е. здесь уже имеем дело с системой случайных величин. Оценка производится по формуле
 . (5.10)
. (5.10)
Определение ошибок и доверительных интервалов для характеристик случайных величин
Для того, чтобы рассмотренными характеристиками случайных величин можно было пользоваться с определенной надежностью, необходимо кроме указанных оценок вычислить для каждой из них ошибки или доверительные интервалы, которые зависят от степени разброса, числа опытов и заданной доверительной вероятности. Ошибка для математического ожидания приближенно определяется по формуле
![]() . (5.11) где– критерий Стьюдента; выбирается по таблицам в зависимости от заданной доверительной вероятностии числа опытов(например, прии,).
. (5.11) где– критерий Стьюдента; выбирается по таблицам в зависимости от заданной доверительной вероятностии числа опытов(например, прии,).
Таким образом, истинное значение математического ожидания с вероятностью находится в доверительном интервале
![]() . (5.12) При заданной точности расчетаи надежности эти же формулы можно использовать для расчета необходимого числа независимых опытов.
. (5.12) При заданной точности расчетаи надежности эти же формулы можно использовать для расчета необходимого числа независимых опытов.
Подобным образом определяется и ошибка величин и
 . (5.13) Считается, что линейная зависимость междуидействительно существует, если
. (5.13) Считается, что линейная зависимость междуидействительно существует, если
![]() . или
. или
 . (5.14) Например, призависимость между исследуемыми величинами действительно имеет место, если
. (5.14) Например, призависимость между исследуемыми величинами действительно имеет место, если
 . (5.15) В противном случае существование зависимости между величинами инедостоверно.
. (5.15) В противном случае существование зависимости между величинами инедостоверно.
Случайная величина
Определение понятия случайной величины
Форма связи между случайными величинами определяется линией регрессии, показывающей, как в среднем изменяется величина
при изменении величины, что характеризуют условным математическим ожиданиемвеличины, вычисляемым при условии, что величинаприняла определенное значение. Таким образом, кривая регрессиинаесть зависимость условного математического ожидания от известного значения
![]() . (5.16) где,–параметры уравнения (коэффициенты).
. (5.16) где,–параметры уравнения (коэффициенты).
Изменения случайной величиныобусловлены изменчивостью стохастически связанной с ней неслучайной величины, а также других факторов, влияющих на, но не зависящих от. Процесс определения уравнения регрессии складывается из двух важнейших этапов: выбора вида уравнения, т. е. задания функции, и расчета параметров уравнения регрессии.
Выбор вида уравнения регрессии
Выбирается этот вид исходя из особенностей изучаемой системы случайных величин. Одним из возможных подходов при этом является экспериментальный подбор типа уравнения регрессии по виду полученного корреляционного поля между величинамииили целенаправленный перебор структур уравнений и оценка каждой из них, например, по критерию адекватности. В случае же, когда имеется определенная априорная (доопытная) информация об объекте, более эффективным является использование для этой цели теоретических представлений о процессах и типах связей между изучаемыми параметрами. Такой подход особенно важен, когда необходимо количественное описание и определение причинно – следственных связей.
Например, лишь имея некоторые представления о теории сталеплавильных процессов, можно делать вывод о причинно – следственных связях для зависимости скорости обезуглероживания от расхода вдуваемого в конвертерную ванну кислорода или обессеривающей способности шлака от его основности и окисленности. А, исходя из представлений о гиперболическом характере зависимости содержания кислорода в металле от содержания углерода, можно заранее предположить, что линейное уравнение зависимости скорости обезуглероживания от интенсивности продувки в области низких содержаний углерода (менее 0,2%) будет неадекватно, и таким образом избежать нескольких этапов экспериментального подбора типа уравнения.
После выбора вида уравнения регрессии производится расчет его параметров (коэффициентов), для чего чаще всего используется метод наименьших квадратов , который будет рассмотрен ниже.
Целью корреляционного анализа является выявление оценки силы связи между случайными величинами (признаками), которые характеризует некоторый реальный процесс.Задачи корреляционного анализа :
а) Измерение степени связности (тесноты, силы, строгости, интенсивности) двух и более явлений.
б) Отбор факторов, оказывающих наиболее существенное влияние на результативный признак, на основании измерения степени связности между явлениями. Существенные в данном аспекте факторы используют далее в регрессионном анализе.
в) Обнаружение неизвестных причинных связей.
Формы проявления взаимосвязей весьма разнообразны. В качестве самых общих их видов выделяют функциональную (полную) и корреляционную (неполную) связи
.
Корреляционная связь
проявляется в среднем, для массовых наблюдений, когда заданным значениям зависимой переменной соответствует некоторый ряд вероятностных значений независимой переменной. Связь называется корреляционной
, если каждому значению факторного признака соответствует вполне определенное неслучайное значение результативного признака.
Наглядным изображением корреляционной таблицы служит корреляционное поле. Оно представляет собой график, где на оси абсцисс откладываются значения X, по оси ординат – Y, а точками показываются сочетания X и Y. По расположению точек можно судить о наличии связи.
Показатели тесноты связи
дают возможность охарактеризовать зависимость вариации результативного признака от вариации признака-фактора.
Более совершенным показателем степени тесноты корреляционной связи
является линейный коэффициент корреляции
. При расчете этого показателя учитываются не только отклонения индивидуальных значений признака от средней, но и сама величина этих отклонений.
Ключевыми вопросами данной темы являются уравнения регрессионной связи между результативным признаком и объясняющей переменной, метод наименьших квадратов для оценки параметров регрессионной модели, анализ качества полученного уравнения регрессии, построение доверительных интервалов прогноза значений результативного признака по уравнению регрессии.
Пример 2

Система нормальных уравнений.
a n + b∑x = ∑y
a∑x + b∑x 2 = ∑y x
Для наших данных система уравнений имеет вид
30a + 5763 b = 21460
5763 a + 1200261 b = 3800360
Из первого уравнения выражаем а и подставим во второе уравнение:
Получаем b = -3.46, a = 1379.33
Уравнение регрессии:
y = -3.46 x + 1379.33
2. Расчет параметров уравнения регрессии.
Выборочные средние.
![]()
![]()
![]()
Выборочные дисперсии:
Среднеквадратическое отклонение
1.1. Коэффициент корреляции
Ковариация
.
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 < r xy < 0.3: слабая;
0.3 < r xy < 0.5: умеренная;
0.5 < r xy < 0.7: заметная;
0.7 < r xy < 0.9: высокая;
0.9 < r xy < 1: весьма высокая;
В нашем примере связь между признаком Y фактором X высокая и обратная.
Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:
1.2. Уравнение регрессии
(оценка уравнения регрессии).
Линейное уравнение регрессии имеет вид y = -3.46 x + 1379.33

Коэффициент b = -3.46 показывает среднее изменение результативного показателя (в единицах измерения у) с повышением или понижением величины фактора х на единицу его измерения. В данном примере с увеличением на 1 единицу y понижается в среднем на -3.46.
Коэффициент a = 1379.33 формально показывает прогнозируемый уровень у, но только в том случае, если х=0 находится близко с выборочными значениями.
Но если х=0 находится далеко от выборочных значений х, то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие значения х, можно определить выровненные (предсказанные) значения результативного показателя y(x) для каждого наблюдения.
Связь между у и х определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе - обратная). В нашем примере связь обратная.
1.3. Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета - коэффициенты.
Средний коэффициент эластичности E показывает, на сколько процентов в среднем по совокупности изменится результат у
от своей средней величины при изменении фактора x
на 1% от своего среднего значения.
Коэффициент эластичности находится по формуле:
![]()
Коэффициент эластичности меньше 1. Следовательно, при изменении Х на 1%, Y изменится менее чем на 1%. Другими словами - влияние Х на Y не существенно.
Бета – коэффициент
показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
![]()
Т.е. увеличение x на величину среднеквадратического отклонения S x приведет к уменьшению среднего значения Y на 0.74 среднеквадратичного отклонения S y .
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации - среднее отклонение расчетных значений от фактических:
![]()
![]()
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Дисперсионный анализ.
Задача дисперсионного анализа состоит в анализе дисперсии зависимой переменной:
∑(y i - y cp) 2 = ∑(y(x) - y cp) 2 + ∑(y - y(x)) 2
где
∑(y i - y cp) 2 - общая сумма квадратов отклонений;
∑(y(x) - y cp) 2 - сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
∑(y - y(x)) 2 - остаточная сумма квадратов отклонений.
Теоретическое корреляционное отношение
для линейной связи равно коэффициенту корреляции r xy .
Для любой формы зависимости теснота связи определяется с помощью множественного коэффициента корреляции
:

Данный коэффициент является универсальным, так как отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных. При построении однофакторной корреляционной модели коэффициент множественной корреляции равен коэффициенту парной корреляции r xy .
1.6. Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = -0.74 2 = 0.5413
т.е. в 54.13 % случаев изменения х приводят к изменению y. Другими словами - точность подбора уравнения регрессии - средняя. Остальные 45.87 % изменения Y объясняются факторами, не учтенными в модели.
Список литературы
- Эконометрика: Учебник / Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2001, с. 34..89.
- Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. Учебное пособие. – 2-е изд., испр. – М.: Дело, 1998, с. 17..42.
- Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2001, с. 5..48.
Прямое токование термина корреляция - стохастическая, вероятная, возможная связь между двумя (парная) или несколькими (множественная) случайными величинами.
Выше говорилось о том, что если для двух СВ (X иY ) имеет место равенство P(XY) =P(X) P(Y) , то величины X и Y считаются независимыми. Ну, а если это не так!?
Ведь всегда важен вопрос - а как сильно зависит одна СВ от другой? И дело в не присущем людям стремлении анализировать что-либо обязательно в числовом измерении. Уже понятно, что системный анализ означает непрерывные вычисления, что использование компьютера вынуждает нас работать с числами , а не понятиями.
Для числовой оценки возможной связи между двумя случайными величинами: Y (со средним M y S y ) и - X (со средним M x и среднеквадратичным отклонением S x ) принято использовать так называемый коэффициент корреляции
R xy = . {2 - 11}
Этот коэффициент может принимать значения от -1 до +1 - в зависимости от тесноты связи между данными случайными величинами.
Если коэффициент корреляции равен нулю, то X и Y называют некоррелированными . Считать их независимыми обычно нет оснований - оказывается, что существуют такие, как правило - нелинейные связи величин, при которых R xy = 0 , хотя величины зависят друг от друга. Обратное всегда верно - если величины независимы , то R xy = 0 . Но, если модуль R xy = 1, то есть все основания предполагать наличие линейной связи между Y и X . Именно поэтому часто говорят о линейной корреляции при использовании такого способа оценки связи между СВ.
Отметим еще один способ оценки корреляционной связи двух случайных величин - если просуммировать произведения отклонений каждой из них от своего среднего значения, то полученную величину -
С xy = S (X - M x) ·(Y - M y)
или ковариацию величин X и Y отличает от коэффициента корреляции два показателя: во-первых, усреднение (деление на число наблюдений или пар X , Y ) и, во-вторых, нормирование путем деления на соответствующие среднеквадратичные отклонения.
Такая оценка связей между случайными величинами в сложной системе является одним из начальных этапов системного анализа, поэтому уже здесь во всей остроте встает вопрос о доверии к выводу о наличии или отсутствии связей между двумя СВ.
В современных методах системного анализа обычно поступают так. По найденному значению R вычисляют вспомогательную величину:
W = 0.5 Ln[(1 + R)/(1-R)] {2 - 12}
и вопрос о доверии к коэффициенту корреляции сводят к доверительным интервалам для случайной величины W, которые определяются стандартными таблицами или формулами.
В отдельных случаях системного анализа приходится решать вопрос о связях нескольких (более 2) случайных величин или вопрос о множественной корреляции .
Пусть X , Y и Z - случайные величины, по наблюдениям над которыми мы установили их средние M x , M y ,Mz и среднеквадратичные отклонения S x , S y , S z .
Тогда можно найти парные коэффициенты корреляции R xy , R xz , R yz по приведенной выше формуле. Но этого явно недостаточно - ведь мы на каждом из трех этапов попросту забывали о наличии третьей случайной величины! Поэтому в случаях множественного корреляционного анализа иногда требуется отыскивать т. н. частные коэффициенты корреляции - например, оценка виляния Z на связь между X и Y производится с помощью коэффициента
R xy.z = {2 - 13}
И, наконец, можно поставить вопрос - а какова связь между данной СВ и совокупностью остальных? Ответ на такие вопросы дают коэффициенты множественной корреляции R x.yz , R y.zx , R z.xy , формулы для вычисления которых построены по тем же принципам - учету связи одной из величин со всеми остальными в совокупности.
На сложности вычислений всех описанных показателей корреляционных связей можно не обращать особого внимания - программы для их расчета достаточно просты и имеются в готовом виде во многих ППП современных компьютеров.
Достаточно понять главное - если при формальном описании элемента сложной системы, совокупности таких элементов в виде подсистемы или, наконец, системы в целом, мы рассматриваем связи между отдельными ее частями, - то степень тесноты этой связи в виде влияния одной СВ на другую можно и нужно оценивать на уровне корреляции.
В заключение заметим еще одно - во всех случаях системного анализа на корреляционном уровне обе случайные величины при парной корреляции или все при множественной считаются "равноправными" - т. е. речь идет о взаимном влиянии СВ друг на друга.
Так бывает далеко не всегда - очень часто вопрос о связях Y и X ставится в иной плоскости - одна из величин является зависимой (функцией) от другой (аргумента).
Связь, которая существует между случайными величинами разной природы, например, между величиной Х и величиной Y, не обязательно является следствием прямой зависимости одной величины от другой (так называемая функциональная связь). В некоторых случаях обе величины зависят от целой совокупности разных факторов, общих для обеих величин, в результате чего и формируется связанные друг с другом закономерности. Когда связь между случайными величинами обнаружена с помощью статистики, мы не можем утверждать, что обнаружили причину происходящего изменения параметров, скорее мы лишь увидели два взаимосвязанных следствия.
Например, дети, которые чаще смотрят по телевизору американские боевики, меньше читают. Дети, которые больше читают, лучше учатся. Не так-то просто решить, где тут причины, а где следствия, но это и не является задачей статистики. Статистика может лишь, выдвинув гипотезу о наличии связи, подкрепить ее цифрами. Если связь действительно имеется, говорят, что между двумя случайными величинами есть корреляция. Если увеличение одной случайной величины связано с увеличением второй случайной величины, корреляция называется прямой. Например, количество прочитанных страниц за год и средний балл (успеваемость). Если, напротив рост одной величины связано с уменьшением другой, говорят об обратной корреляции. Например, количество боевиков и количество прочитанных страниц.
Взаимная связь двух случайных величин называется корреляцией, корреляционный анализ позволяет определить наличие такой связи, оценить, насколько тесна и существенна эта связь. Все это выражается количественно.
Как определить, есть ли корреляция между величинами? В большинстве случаев, это можно увидеть на обычном графике. Например, по каждому ребенку из нашей выборки можно определить величину Х i (число страниц) и Y i (средний балл годовой оценки), и записать эти данные в виде таблицы. Построить оси Х и Y, а затем нанести на график весь ряд точек таким образом, чтобы каждая из них имела определенную пару координат (Х i , Y i) из нашей таблицы. Поскольку мы в данном случае затрудняемся определить, что можно считать причиной, а что следствием, не важно, какая ось будет вертикальной, а какая горизонтальной.


Если график имеет вид а), то это говорит о наличии прямой корреляции, в
случае, если он имеет вид б) - корреляция обратная. Отсутствие корреляции
С помощью коэффициента корреляции можно посчитать насколько тесная связь
существует между величинами.
Пусть, существует корреляция между ценой и спросом на товар. Количество купленных единиц товара в зависимости от цены у разных продавцов показано в таблице:
Видно, что мы имеем дело с обратной корреляцией. Для количественной оценки тесноты связи используют коэффициент корреляции:

Коэффициент r мы считаем в Excel, с помощью функции f x , далее статистические функции, функция КОРРЕЛ. По подсказке программы вводим мышью в два соответствующих поля два разных массива (Х и Y). В нашем случае коэффициент корреляции получился r= - 0,988. Надо отметить, что чем ближе к 0 коэффициент корреляции, тем слабее связь между величинами. Наиболее тесная связь при прямой корреляции соответствует коэффициенту r, близкому к +1. В нашем случае, корреляция обратная, но тоже очень тесная, и коэффициент близок к -1.
Что можно сказать о случайных величинах, у которых коэффициент имеет промежуточное значение? Например, если бы мы получили r=0,65. В этом случае, статистика позволяет сказать, что две случайные величины частично связаны друг с другом. Скажем на 65% влияние на количество покупок оказывала цена, а на 35% - другие обстоятельства.
И еще одно важное обстоятельство надо упомянуть. Поскольку мы говорим о случайных величинах, всегда существует вероятность, что замеченная нами связь - случайное обстоятельство. Причем вероятность найти связь там, где ее нет, особенно велика тогда, когда точек в выборке мало, а при оценке Вы не построили график, а просто посчитали значение коэффициента корреляции на компьютере. Так, если мы оставим всего две разные точки в любой произвольной выборке, коэффициент корреляции будет равен или +1 или -1. Из школьного курса геометрии мы знаем, что через две точки можно всегда провести прямую линию. Для оценки статистической достоверности факта обнаруженной Вами связи полезно использовать так называемую корреляционную поправку:
В то время как задача корреляционного анализа - установить, являются ли данные случайные величины взаимосвязанными, цель регрессионного анализа - описать эту связь аналитической зависимостью, т.е. с помощью уравнения. Мы рассмотрим самый несложный случай, когда связь между точками на графике может быть представлена прямой линией. Уравнение этой прямой линии Y=аХ+b, где a=Yср.-bХср.,

Зная , мы можем находить значение функции по значению аргумента в тех точках, где значение Х известно, а Y - нет. Эти оценки бывают очень нужны, но они должны использоваться осторожно, особенно, если связь между величинами не слишком тесная.
Отметим также, что из сопоставления формул для b и r видно, что коэффициент не дает значение наклона прямой, а лишь показывает сам факт наличия связи.